
// Tagged with AI-first Entrepreneurs
Something important is happening to knowledge work, and it is moving faster than most people realize. The most visible example is software development: the coder who once prided themselves on writing clean, elegant functions is being replaced not by AI, exactly, but by a different kind of engineer. One who thinks in systems, diagnoses agent failures, and routes work across dozens of parallel processes rather than writing each line themselves. But the transition from functional expert to agent manager is not just about coding. It is the defining shift across all of knowledge work. In forward-looking industries, knowledge workers are already spending far more time in ChatGPT/Claude than in dashboards and ticketing systems.
Now, the key question is, what does it mean for application-level software?
We’d refer to a rather non-controversial assumption for the rest of this article’s argument: any successful application software, whether AI-native or not, needs to be designed user-first.
Therefore, what’s scary and exciting at the same time for application builders is that their end users are rapidly transforming and sometimes shrinking in number. At the same time, I believe that domains with human-oriented liability and accountability systems will continue to have human jobs for at least a decade. Domains requiring explicit licensing (doctors, lawyers, CPAs, etc.) are obvious examples. But accountability systems also exist in sales, consulting, HR, etc (Who do you fire if things go wrong?). Those enterprise users will need purpose-built application software that not only gets the job done but also helps them remain positively accountable.
The sales executive of tomorrow is a data-literate operator who can construct custom go-to-market agents, read their outputs critically, and intervene when the logic breaks down.
The lawyer does not disappear, but the role shifts from synthesising caselaw to that of an expert negotiator who can rapidly parse what an army of agents has surfaced.
The accountant moves from executing reconciliations to understanding where agents make errors and how to design safeguards against fraud.
In each case, the underlying trade is the same: routine functional execution is absorbed by AI, while uniquely human capabilities of judgment, communication, accountability, and deep contextual understanding become more central, not less.
Three human skills will consistently matter more in this world:
- The analytical capacity to launch and manage agent workflows
- Genuine human relationship-building for high-stakes decisions
- Actual deep domain expertise, particularly at the PhD or post-doctoral level, to debug and validate what agents produce.
Everything else is at risk of compression.
The largest opportunity in application software will be building for analytical humans working with swarms of agents in their respective domains.
Anthropic, Cursor, and OpenAI themselves likely keep building such tooling for software developers. However, a compelling commercial opportunity exists for application-level startups in other domains. Frontier Labs will still try to compete everywhere with virtually infinite resources, but the unfair advantage that exists for fully verifiable domains like coding is weaker in others. That is where the largest venture opportunities lie in application software.
DNA of the eventual application winners
Winning applications of the future will meet users where they are, with the primary goal of helping them launch and manage swarms of agents that they uniquely love.
I predict the following key characteristics for eventual winners in the enterprise AI Applications category:
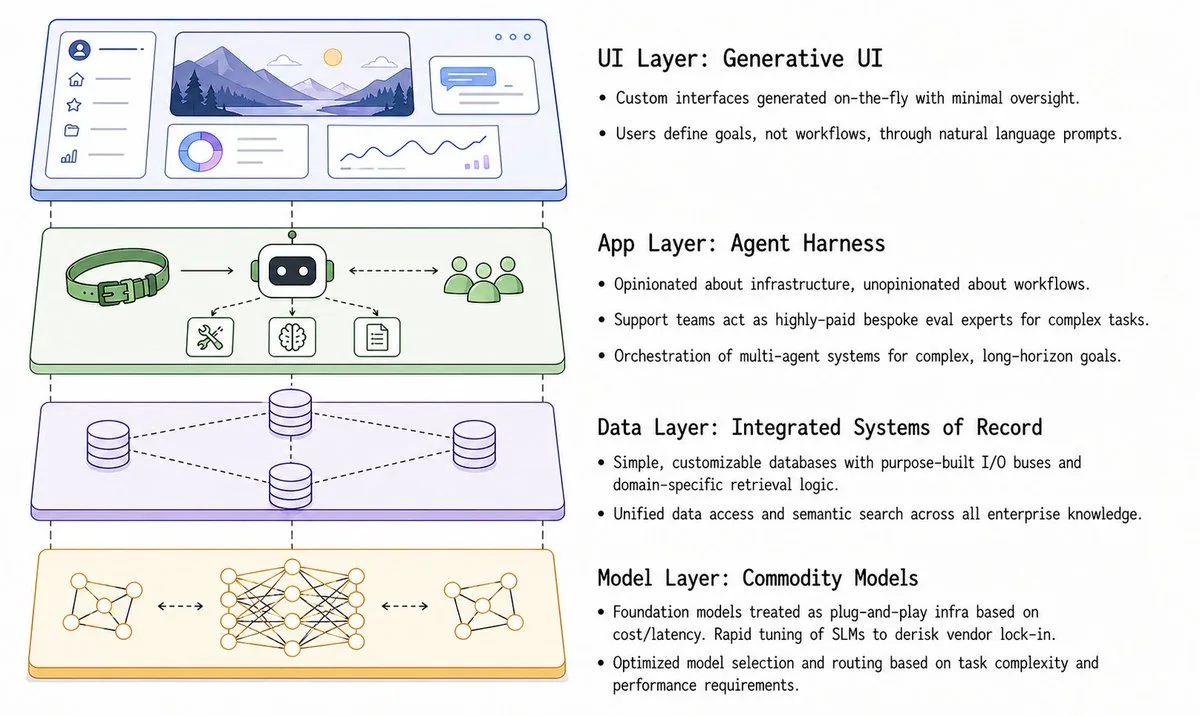
- App builder instead of apps with static feature sets: The winning application companies will look less like today’s applications and more like infrastructure platforms that let users build the workflows and mini-applications that best fit their needs.
- Generative UI: The UI will be generated on the fly with minimal human oversight and tailored to each user.
- Integrated systems of record: Core databases will need to be integrated into the app builder for the product to be sticky, and future systems of record will likely be low-cost, simple databases with customizable and purpose-built input and output buses.
- Self-evolving systems of action: Each action an agent takes will be recorded for auditability and continual learning, and winning applications will create a unique system of action for each customer that becomes hard to replace over time if those actions are stored as embeddings and accessed in a proprietary way.
- Treating foundation models as commodity infrastructure: Applications will support plug-and-play model selection based on accuracy, cost, and latency needs, and they will rapidly tune smaller language models where relevant, reducing concentration risk from a single model vendor. A common pitfall is asking, “Okay, how do I build my own domain-specific model to remain competitive vs frontier labs?” The reality is that there needn’t be a single end-to-end model to win in your domain. There will always be certain tasks that don’t need much domain-specific tuning, while others do. It’s prudent to focus on the latter as the main competitive edge. As always, the beauty lies in nuances!
- Domain-specific retrieval logic: Domain-specific agents will know which sources to prioritize and will have custom infrastructure to store and process the most relevant datasets efficiently.
- Reliability guarantees through in-house evaluations: Customer support teams at winning companies will be staffed with highly paid domain experts who guide customers through evaluations and may offer bespoke evaluation services.
None of the currently popular AI application companies satisfies all of the above criteria, likely because the transition of enterprise workers from functional experts to agent managers is still in its early stages.
Therefore, the vast majority of the first wave of heavily funded AI application startups do not have the winning products of the future, and they will either relaunch or struggle against a second generation of applications.
Moats for AI native application software
Traditional product-led moats for software companies are shrinking:
- Workflow depth: New enterprise users will want custom workflows with simple UIs, with most tasks handled in the background
- Integrations: integration code, like other code, is being automated. Additionally, computer-use agents reduce the defensibility of even complex or tightly controlled integrations
- Customer data: Customer data on most incumbent SaaS platforms is relatively easy to export and difficult to lock in
Winning application companies now need new types of moats:
Proprietary industry data
Data can be a moat in some application categories, but it’s worth being specific about which kinds of data create real differentiation. Customer-specific data is (a) often not allowed to be used for training, especially for enterprise customers, and (b) frequently only relevant to the company that produced it. However, two types of data can create durable advantages:
- Industry-wide data collection that benefits from amortization: think Crunchbase for private financings, Apollo for buyer lead datasets, or AlphaSense for company filings. Every $ invested in data collection is paid for by multiple customers, and over time, this becomes a moat. It can create a right to win in competitive categories by building agents on top of it.
- Data with opt-in network effects: easier to implement in categories with a large SMB long tail, where customers may be more open to sharing data with a network. For example, an AI-native business communication product for procurement and logistics. Every added node (a new customer or supplier) adds more data for intelligent matching.
Domain-specific models
In non-verifiable domains, the “best” model depends not only on the volume of data, but also on its quality. Deep-domain startups can often identify stronger post-training approaches than general-purpose AI labs.
A particularly aggressive case may show up even in coding: watch whether Cursor develops a comparable or better coding model than Anthropic. If they can get to even 90%, the opportunity becomes much more real for other domains.
At the same time, when investing in early stages, we can and should assume that:
- Domain-specific post-training will be necessary for only a small set of use cases, and application companies can get off the ground without it
- For a wide range of use cases, strong application companies will use cheap-to-run open source models
- Switching between models will be abstracted at the infrastructure layer, and the user should never need to see it (e.g., do we care which routes Zoom auto-switches between to transfer AV packets?)
Proprietary systems of action
Software companies can still fulfil obligations to hand over customer data if asked, for example, when a customer wants to switch out. But if they capture action trails in a way that makes their agents effective, those same action trails will not be easily reusable by a competing vendor. Traditional SaaS exposed most of its complexity in the UI, but new-age SaaS will hide much of its key complexity in the embedding space.
———
If you’re an early-stage founder looking to start up a B2B software application company today and don’t have a $100M in funding in your bank account, most categories would look over-capitalized and impossible to penetrate from the outside. However, to your favour, the rules of the sport have changed – the user persona is net new, and the defining moats in an AI-abundant world look completely different as well. Therefore, on closer look, the opportunity would look very much open. Time to capitalize on the mover advantage!
// Tagged with AI-first Entrepreneurs





